CASAS.h5py¶
casas_hdf5_doc_master implements pyActLearn.CASAS.h5py.CASASHDF5.
Dataset Structure¶
HDF5 is a data model, library and file format for storing and managing data. h5py package is the python interface to read and write HDF5 file. You can open and view the HDF5 file using hdfviewer.
The pre-processed feature array x is stored as dataset /features.
Corresponding target labels is stored as dataset /targets.
The corresponding time for each entry is stored at /time as array of bytes (HDF5 does not support str).
The meta-data of the smart home is stored as attributes of the root node. The table below summarizes the description of all those attributes.
| Attribute | Description |
|---|---|
| bg_target | Name of background activity. |
| comment | Description of the dataset. |
| days | List of start and stop index tuple of each segment when the dataset is splitted by days. |
| weeks | List of start and stop index tuple of each segment when the dataset is splitted by weeks. |
| features | Feature name corresponding to each column in /features dataset. |
| targets | List of activity labels. |
| target_color | List of color string for each activity for visualization. |
| sources | List of dataset names in the file. |
| sensors | List of sensor names |
The image below gives a glimpse of the hdf5 structure in hdfviewer.
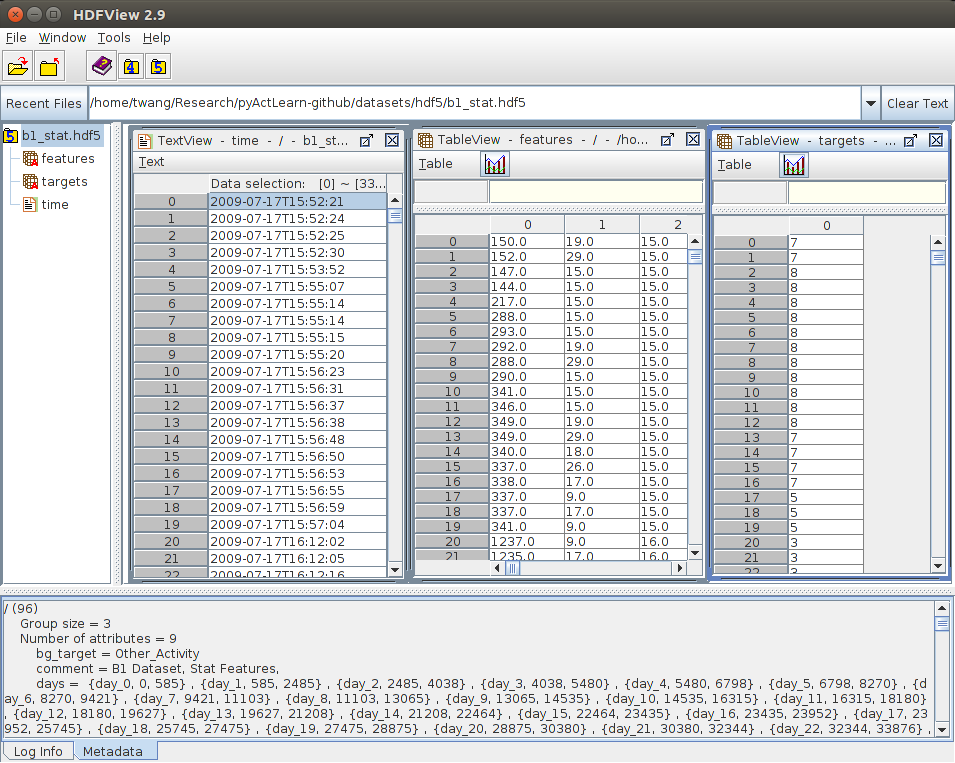
Smart home pre-processed data in hdf5 format.
Load and Fetch Data from HDF5¶
pyActLearn.CASAS.h5py.CASASHDF5 provides multiple interfaces for accessing and loading the data
from hdf5 file. The dataset is usually split by weeks and days. Function
pyActLearn.CASAS.h5py.CASASHDF5.fetch_data() will load the time, features and target labels of the
time frame provided via the start split and end split names.
Here is the code snip to load the data from splits to train a support vector machine.
import sklearn.svm
from pyActLearn.CASAS.h5py import CASASHDF5
# Load dataset
ds = CASASHDF5(path='twor_statNormPerSensor.hdf5')
# Training
time, feature, target = ds.fetch_data(start_split='week_1', stop_split='week_4')
x = feature
y = target.flatten().astype(np.int)
model = sklearn.svm.SVC(kernel='rbf')
model.fit(x, y)
# Testing
time, feature, target = ds.fetch_data(start_split='week_1', stop_split='week_4')
x = feature
y = model.predict(x)
API Reference¶
-
class
pyActLearn.CASAS.h5py.CASASHDF5(filename, mode='r', driver=None)[source]¶ Bases:
objectCASASHDF5 Class to create and retrieve CASAS smart home data from h5df file
The data saved to or retrieved from a H5PY data file are pre-calculated features by
CASASDataclass. The H5PY data file also contains meta-data about the dataset, which include description for each feature, splits by week and/or splits by days.Variables: _file (
h5py.File) –h5py.Fileobject that represents root group.Parameters: -
create_comments(comment)[source]¶ Add comments to dataset
Parameters: comment ( str) – Comments to the dataset
-
create_features(feature_array, feature_description)[source]¶ Create Feature Dataset
Parameters: - feature_array (
numpy.ndarray) – Numpy array holding calculated feature vectors - feature_description (
listofstr) – List of strings that describe each column of feature vectors.
- feature_array (
-
create_sensors(sensors)[source]¶ Add sensors list to attributes
If the sensor IDs in the dataset is not binary coded, there is a need to provide the sensor list to go along with the feature vectors.
Parameters: sensors ( listofstr) – List of sensor name corresponds to the id in the feature array.
-
create_targets(target_array, target_description, target_colors)[source]¶ Create Target Dataset
Parameters: - target_array (
numpy.ndarray) – Numpy array holding target labels - target_description (
listofstr) – List of strings that describe each each target class. - target_colors (
listofstr) – List of color values corresponding to each target class.
- target_array (
-
create_time_list(time_array)[source]¶ Create Time List
Parameters: time_array ( listofdatetime) – datetime corresponding to each feature vector in feature dataset.
-
fetch_data(start_split=None, stop_split=None, pre_load=0)[source]¶ Fetch data between start and stop splits
Parameters: Returns: - Returns a tuple of all sources sliced by the split defined.
The sources should be in the order of (‘time’, ‘feature’, ‘target’)
Return type:
-
get_bg_target()[source]¶ Get the description of the target class considered background in the dataset.
Returns: Name of the class which is considered background in the dataset. Usually it is ‘Other_Activity’. Return type: str
-
get_bg_target_id()[source]¶ Get the id of the target class considered background.
Returns: The index of the target class which is considered background in the dataset. Return type: int
-
get_days_info()[source]¶ Get splits by day.
Returns: - List of (key, value) tuple, where key is the name of the split and value is
- number of items in that split.
Return type: Listoftuple
-
get_feature_description_by_index(i)[source]¶ Get the description of feature column \(i\).
Parameters: i ( int) – Column index.Returns: Corresponding column description. Return type: str
-
get_target_color_by_index(i)[source]¶ Get the color string of target class \(i\).
Parameters: i ( int) – Class index.Returns: Corresponding target class color string. Return type: str
-
get_target_description_by_index(i)[source]¶ Get target description by class index \(i\).
Parameters: i ( int) – Class index.Returns: Corresponding target class description. Return type: str
-
get_target_descriptions()[source]¶ Get list of target descriptions
Returns: List of target class description strings. Return type: listofstr
-
get_weeks_info()[source]¶ Get splits by week.
Returns: - List of (key, value) tuple, where key is the name of the split and value is
- number of items in that split.
Return type: Listoftuple
-
is_bg_target(i=None, label=None)[source]¶ Check if the target class given by :param:`i` or :param:`label` is considered background
Parameters: Returns: True if it is considered background.
Return type:
-
num_between_splits(start_split=None, stop_split=None)[source]¶ Get the number of item between splits
Parameters: Returns: The number of items between two splits.
Return type:
-